背景
在实际的开发过程中,计数统计是一项非常常见的功能性需求。无论是在内容类平台,还是社交类应用中,都广泛存在着计数类场景。例如,在博客系统中,我们需要展示不同分类下的文章数量;在微博系统中,则可能涉及到展示粉丝数量、关注数、微博数、评论数等多维度数据。
数据的变更频率和C端访问压力,往往决定了不同的技术方案选型。为了高效、稳定地支撑业务所需的计数统计功能,业界通常有3种主流方案可供选择:
- 基于 RDBMS 的 COUNT+GROUPBY 统计查询;
- 基于 Elasticsearch 倒排索引的聚合统计;
- 基于最终一致性的计数统计方案。
本文我们将深入探讨在高频交易场景下,订单计数功能应该怎么去设计和实现。我们的实际单量在百万级/天,C端需要对客展示 ‘待支付’ 和 ‘待出行’ 等2种STATE的的订单数量,如果直接使用COUNT+GROUPBY语句去交易库中查询会对DB产生较大压力。尽管在RDBMS中,单片千万数量级的统计查询在命中联合索引的情况下,能够做到毫秒级响应,但为了避免并发量过大导致系统雪崩,以及同时考虑到这个订单计数功能并非主流程的核心功能,因此我们决定采用最终一致性的订单计数方案。
基于最终一致性的订单计数方案
如图1所示,当交易系统成功流转订单STATE(to 待支付、to 待出行)后,会异步通知订单计数服务。待计数服务消费到指定用户的订单数量变更事件后,会自行计算并更新CACHE中的订单总数(比如:待支付:0,待出行:1)。而当用户发起订单数量查询请求时,计数服务直接从CACHE中获取订单数量返回,不再需要每次都通过COUNT+GROUPBY语句实时统计查询,从而大幅降低DB的负载压力。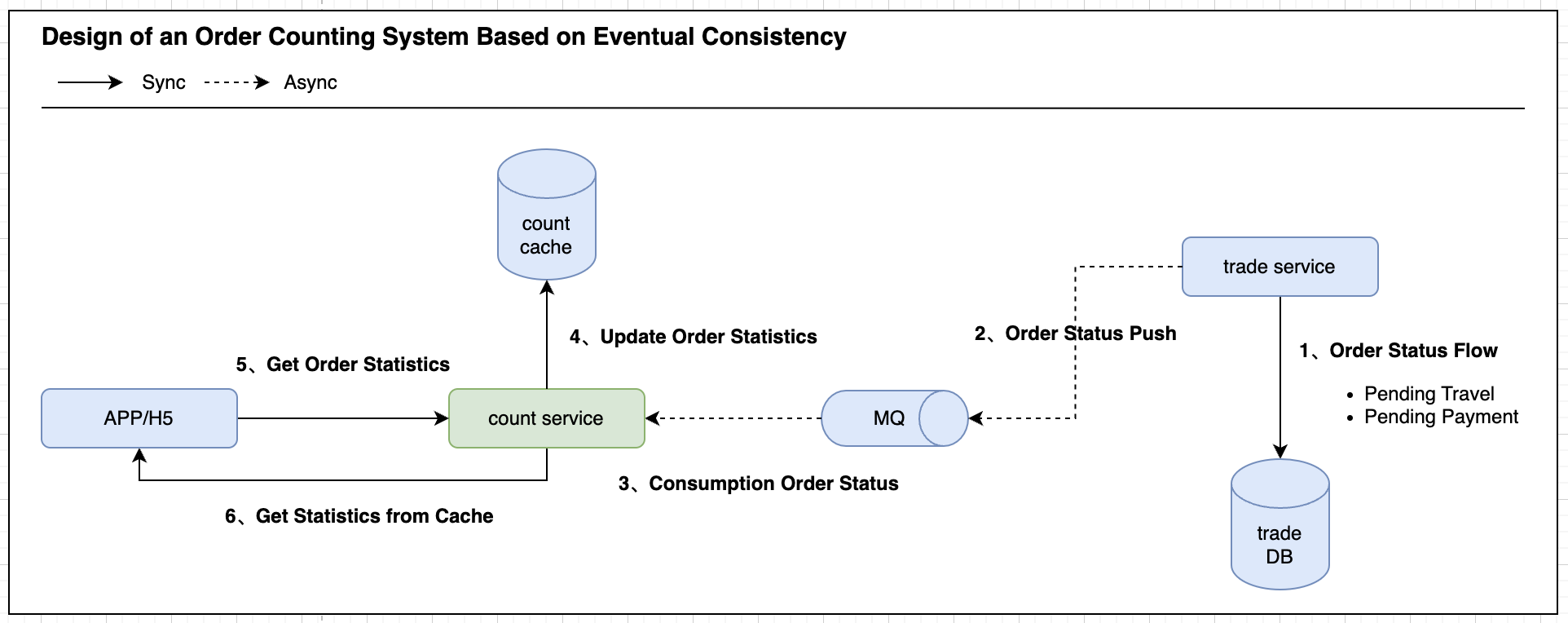
基于上述方案,大家重点思考2个问题:
- 存量数据如何预热?
- 如何保证CACHE中的订单数量和交易库中的真实订单数量的数据一致性?
存量数据预热
正常情况下,我们很容易想到,当C端发起查询请求时,如果计数服务从CACHE中获取不到数据,那么计数服务可以先同步去交易库中执行COUNT+GROUPBY语句再预热。
在此大家需要注意,在分布式环境下,任意执行环节出错都会影响数据的一致性。如图2所示,假设交易系统正常流转完订单STATE(将STATE从「待支付」变更为「待出行」)后,此时DB中的真实用户订单数量为:待支付0,待出行1;交易系统下发变更事件给计数服务时如果发生网络抖动,C端发起查询时由于CACHE MISS,计数服务由于直接同步向交易库执行COUNT+GROUPBY语句再预热,这时尽管用户的订单数量能够正确显示为:待支付0,待出行1,但后续网络抖动恢复后,由于计数服务存在延迟消费,必然会导致正确的用户数据被错误篡改,从而产生脏读(待支付-1,待出行2)。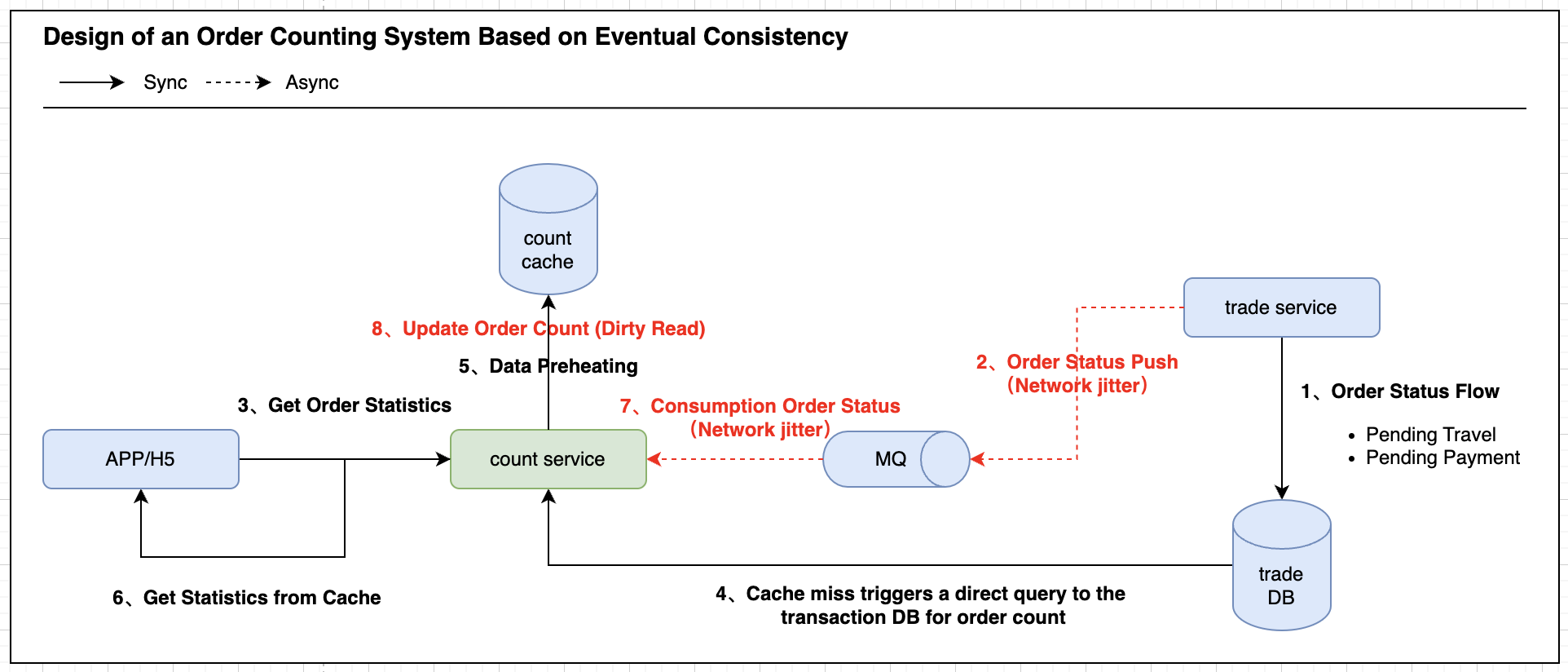
那如果查询时CACHE MISS且完成数据预热后,对于因网络抖动导致的异常变更事件不再更新CACHE,是否就能确保数据一致性?虽然想法很美好,但这似乎并不现实,因为这根本做不到,计数服务如何感知因网络抖动导致的异常变更事件?但却能基于EVENT ID去做幂等去重,防止计数服务因重复消费导致的数据不一致问题。
那查询时,计数服务穿透到DB获取数据后直接返回而不再进行预热是否可行?意思就是当C端发起查询时IS CACHE MISS,计数服务都不再执行预热动作,而是依靠写时更新(即:交易系统在流转完订单STATE后,下发事件给计数服务,计数服务根据IS CACHE MISS来决定执行预热事件还是变更事件),如图3所示: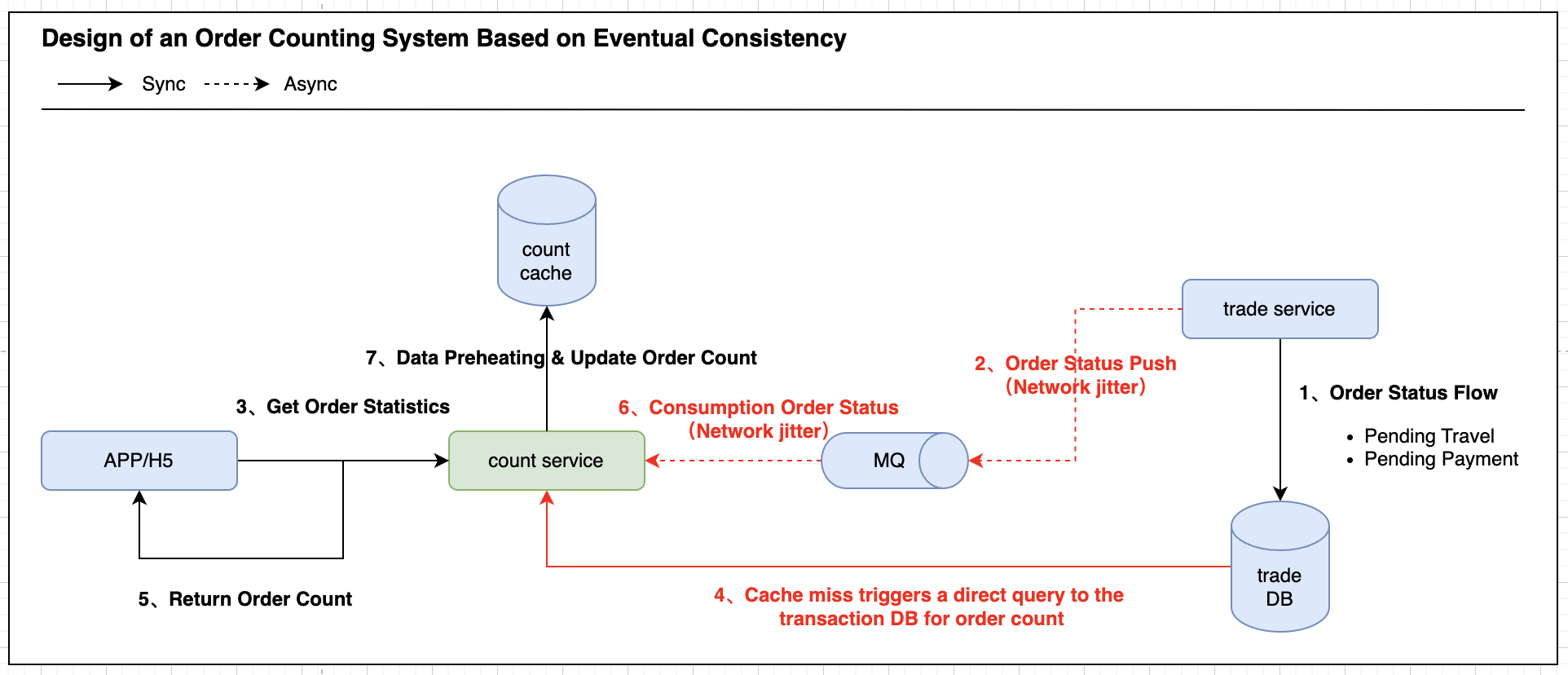
写时更新尽管可以从最大程度上确保CACHE和DB的数据一致性,但从业务的执行流程上来说,如果用户长时间没有发生实际的交易行为,那么大量的查询请求将会导致交易库被击穿,从而产生雪崩。那数据预热到底是由写请求还是读请求发起?答案就是读/写请求CACHE MISS时都要进行数据预热操作。
读操作计数服务发起预热有2种情况,分别是CACHE MISS和CACHE失效(逻辑失效,下一小节会讲到),这2种情况都应该先直接返回脏数据(CACHE MISS时返回0),Lock acquired时异步发起预热事件,Failed to acquire lock时则Failfast,不重试的原因是为了避免无效的重复预热动作,因为CACHE不失效没必要进行全量数据预热。而写时要根据IS CACHE MISS来决定是执行预热事件还是变更事件,Lock acquired时如果CACHE MISS要把变更事件转为预热事件执行,而Failed to acquire lock时要执行Failover,以便于变更事件的正常流转,降低对客脏读风险。在此大家需要注意,最终一致性方案的本质就是可用优先+高频近似正确原则,业务上务必要具备和支持短期数据不一致的容错性。
数据校准
换句话说,最终一致性方案就是业务上允许数据存在一定程度上的脏读,但要尽可能缩短数据不一致的窗口期,尽可能降低对客体验影响。如图4所示,针对脏数据,我们的思考方向不再是强一致性,而是尽可能保证一致性,解决方案就是数据校准,那应该怎么校准?给CACHE数据加上一份过期时间(逻辑失效),单位可以是秒、分、小时,这根据具体的业务场景而定,过期时间决定了数据不一致的窗口期大小,如果窗口期太长,对客影响会非常明显,如果窗口期过短,又会加重DB负载,所以业务上我们要在用户体验和系统性能之间折中权衡。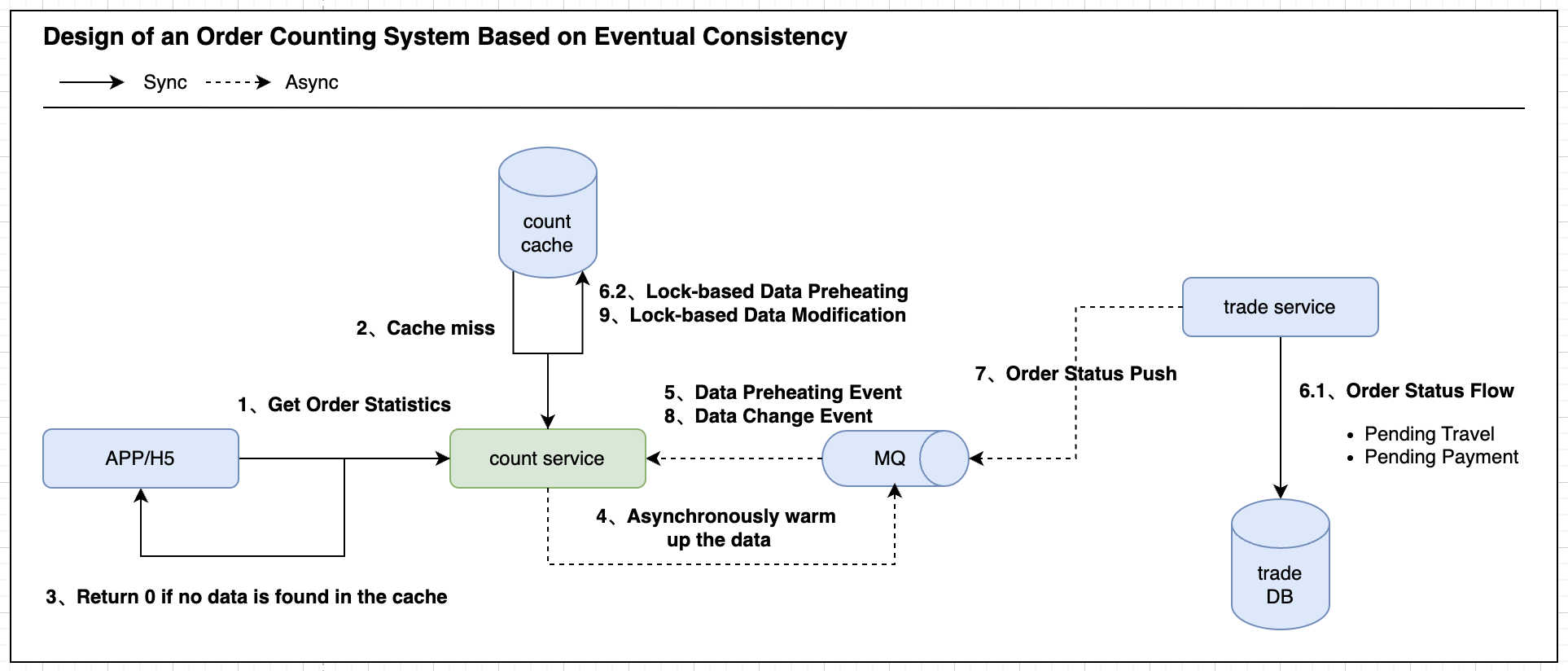
这里之所以没有设置CACHE的TTL,是因为如果CACHE MISS时返回0,那么数据预热后假设返回1,那么数据会持续在0和1之间切换,对客体验非常差,所以我们选择数据常驻内存,通过业务过期手段来使数据看上去是规律递增而不是无规律乱跳的,尽可能增强用户体验。也就是说,CACHE的数据结构在设计时要显式指定一个业务过期字段,如图5所示:
写在最后,在 分布式系统架构设计中,方案永远无法做到“既要… 又要… 还要…”。

